Dalam upaya mengembangkan pengalaman AI mobile yang prima, Samsung mengunjungi pusat-pusat penelitian mereka di seluruh dunia, termasuk Samsung R&D Institute Indonesia (SRIN).
Tujuannya? Memahami proses di balik fitur Galaxy AI yang saat ini mendukung 16 bahasa, termasuk bahasa Indonesia. Namun seperti apa sesungguhnya yang terlibat dalam mengajarkan bahasa baru kepada AI?
Menurut SRIN, kunci utama adalah data yang berkualitas dan relevan. “Setiap bahasa menuntut cara yang berbeda untuk memproses data. Jadi, kami menggali lebih dalam untuk memahami kebutuhan linguistik dan keunikan dari Bahasa Indonesia,” ungkap Junaidillah Fadlil, kepala divisi AI SRIN, seperti dikutip dari siaran pers Samsung.
Fadlil menjelaskan bahwa pengembangan bahasa lokal harus didasari pemahaman dan ilmu pengetahuan yang mendalam. Karena itu, penambahan bahasa ke Galaxy AI dimulai dengan merencanakan pengumpulan informasi secara legal dan etis.
Tiga proses inti
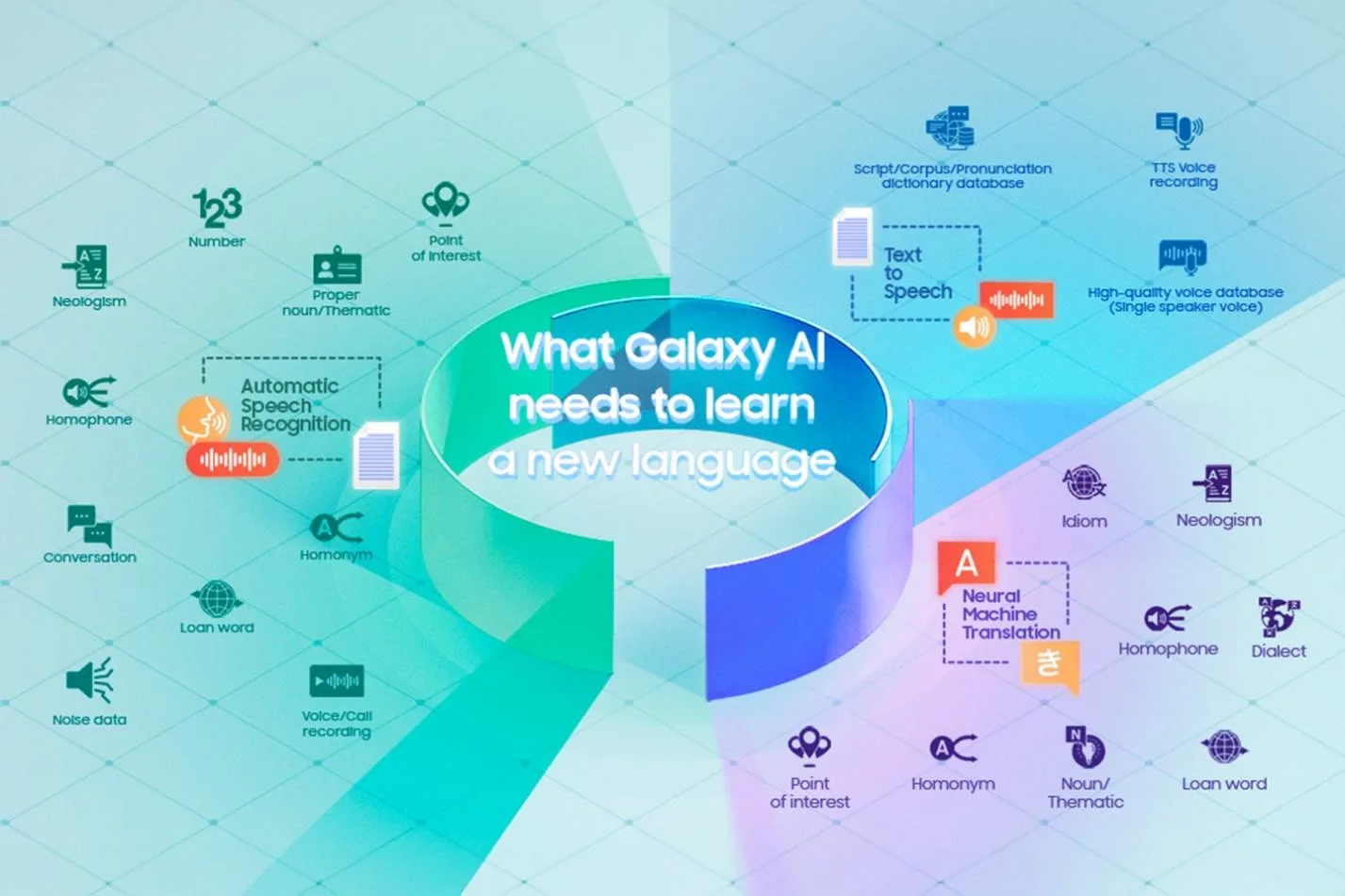
Fitur Galaxy AI seperti Live Translate menjalankan tiga proses inti: pengenalan ucapan otomatis (automatic speech recognition/ASR), mesin terjemahan (neural machine translation/NMT), dan teks-ke-suara (text-to-speech/TTS). Masing-masing membutuhkan kumpulan data yang unik.
Untuk ASR misalnya, diperlukan rekaman suara yang mencakup beragam situasi dalam berbagai kondisi, dilengkapi transkripsi teks yang akurat.
Menambahkan suara lalu lintas ke rekaman saja tidak cukup kalau menurut Muchlisin Adi Saputra selaku pemimpin tim ASR, sebab mereka juga harus merekam suara autentik seperti orang memanggil atau mengetik di kafe atau lingkungan kerja yang lain.
Sifat bahasa yang dinamis juga menjadi pertimbangan. Saputra menambahkan, “Kita perlu terus memperbarui bahasa slang terbaru dan cara penggunaannya. Kami banyak temukan dari media sosial!”

Untuk NMT, data yang digunakan harus berisi banyak teks terjemahan agar AI dapat memahami kata-kata baru, kata asing, kata benda, dan angka dalam konteks.
Muhammad Faisal dari tim NMT mengungkapkan, “Menerjemahkan Bahasa Indonesia penuh dengan tantangan. Penggunaan makna kontekstual dan implisit yang luas bergantung pada petunjuk sosial dan situasional.”
Sementara untuk TTS, dibutuhkan rekaman yang melibatkan beragam suara dan nada disertai konteks bagaimana setiap kata diucapkan dalam situasi yang berbeda.
“Rekaman suara yang baik mempercepat pekerjaan yang dilakukan karena mencakup satuan bunyi terkecil yang diperlukan AI untuk membedakan makna,” papar Harits Abdurrohman selaku pemimpin pengembangan TTS.
Kolaborasi tingkat dunia
Mengumpulkan data yang dibutuhkan bukan perkara mudah. SRIN pun berkolaborasi dengan para ahli linguistik Indonesia serta rekan-rekan di pusat penelitian Samsung di seluruh dunia.
“Tantangan ini membutuhkan kombinasi kreativitas, ketangkasan, dan keahlian dalam Bahasa Indonesia dan machine learning. Filosofi Samsung yang terus membuka ruang kolaborasi memainkan peran penting dalam menyelesaikan pekerjaan ini,” ungkap Fadlil.

Kerja sama ini tidak hanya meningkatkan teknologi, tetapi juga mempererat hubungan budaya. Ketika bergabung dengan tim di Bangalore misalnya, SRIN mengamati tradisi lokal dan menjalin ikatan layaknya keluarga.
Fadlil merasa bangga dengan pencapaian ini sebagai proyek AI pertama SRIN. “Tentunya, ini bukan yang terakhir karena kami akan terus menyempurnakan dan meningkatkan kualitas model AI kami. Perluasan ini tidak hanya mencerminkan nilai-nilai kami, tetapi juga menghormati serta mengintegrasikan identitas budaya Indonesia melalui bahasa,” pungkasnya.